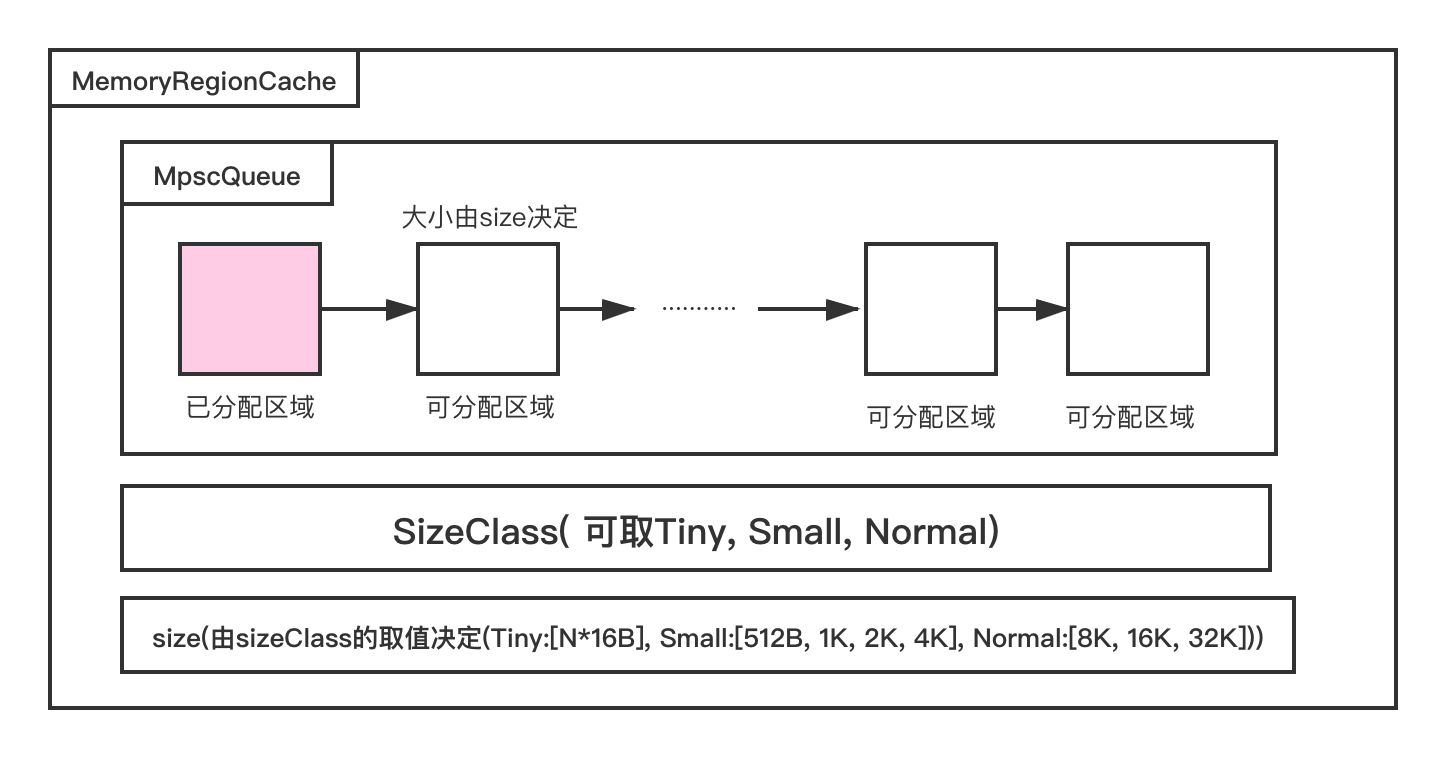
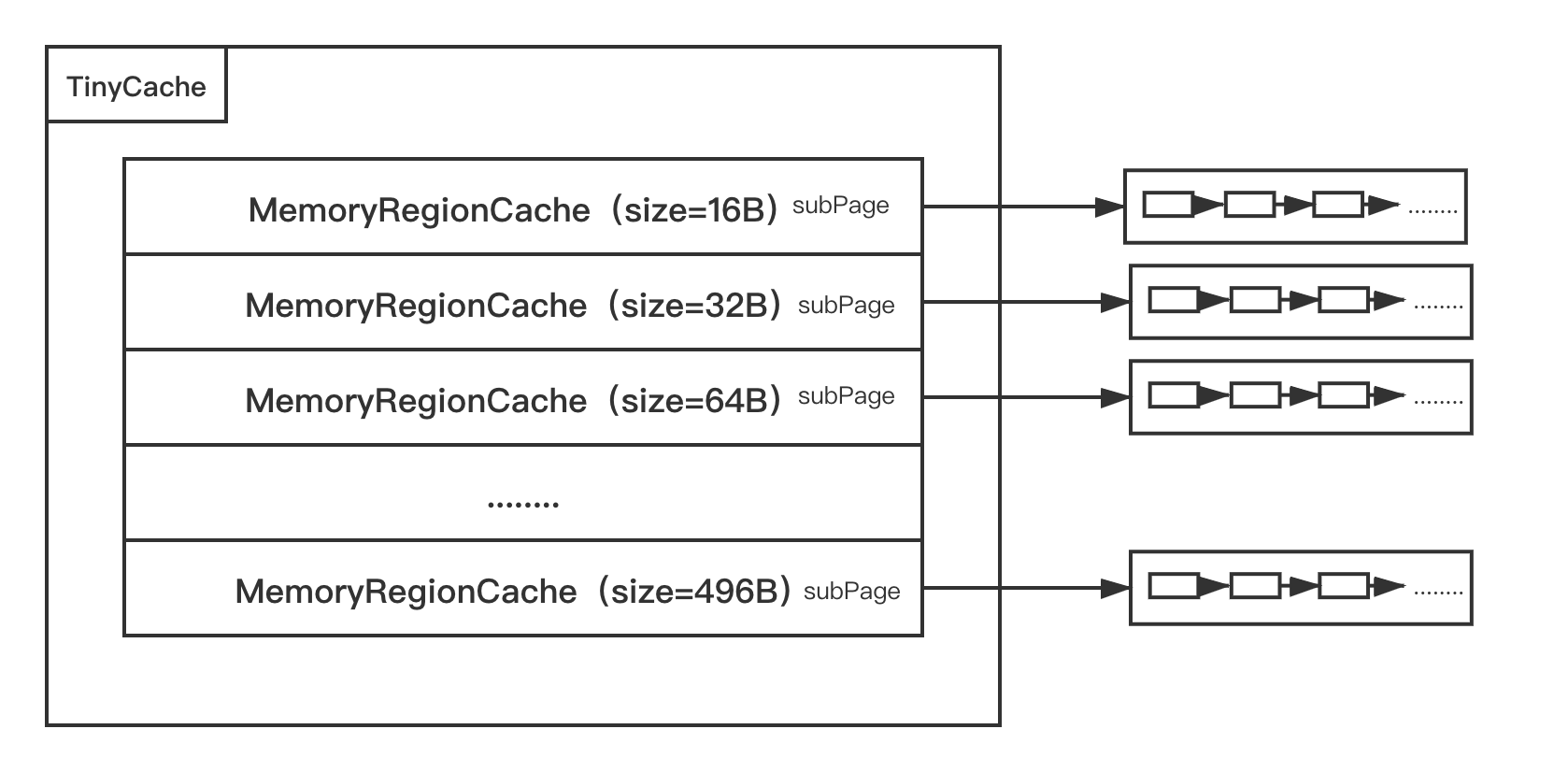
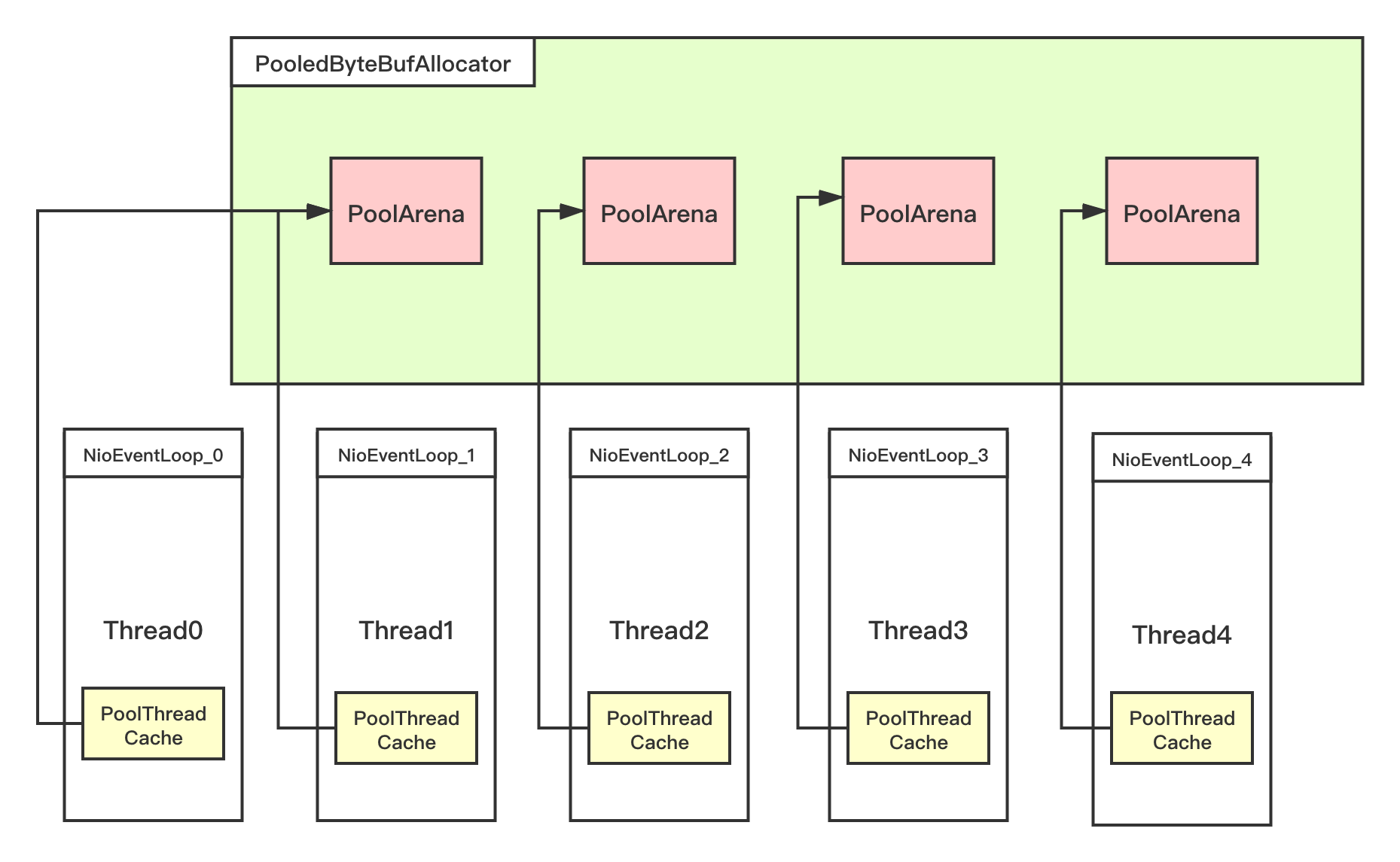
finalclassPoolThreadCache{ ... ... // Hold the caches for the different size classes, which are tiny, small and normal. privatefinal MemoryRegionCache<byte[]>[] tinySubPageHeapCaches; privatefinal MemoryRegionCache<byte[]>[] smallSubPageHeapCaches; privatefinal MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches; privatefinal MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches; privatefinal MemoryRegionCache<byte[]>[] normalHeapCaches; privatefinal MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena, int tinyCacheSize, int smallCacheSize, int normalCacheSize, int maxCachedBufferCapacity, int freeSweepAllocationThreshold) { checkPositiveOrZero(maxCachedBufferCapacity, "maxCachedBufferCapacity"); this.freeSweepAllocationThreshold = freeSweepAllocationThreshold; this.heapArena = heapArena; this.directArena = directArena; if (directArena != null) { // 在这里createSubPageCaches就是创建上面所说的Tiny池 tinySubPageDirectCaches = createSubPageCaches( tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny); // 创建Small池 smallSubPageDirectCaches = createSubPageCaches( smallCacheSize, directArena.numSmallSubpagePools, SizeClass.Small);
numShiftsNormalDirect = log2(directArena.pageSize); // 创建Normal池 normalDirectCaches = createNormalCaches( normalCacheSize, maxCachedBufferCapacity, directArena); directArena.numThreadCaches.getAndIncrement(); } else { // No directArea is configured so just null out all caches tinySubPageDirectCaches = null; smallSubPageDirectCaches = null; normalDirectCaches = null; numShiftsNormalDirect = -1; }
// Heap的情况和Direct的情况极为相似,这里不作过多阐述 if (heapArena != null) { // Create the caches for the heap allocations tinySubPageHeapCaches = createSubPageCaches( tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny); smallSubPageHeapCaches = createSubPageCaches( smallCacheSize, heapArena.numSmallSubpagePools, SizeClass.Small);
heapArena.numThreadCaches.getAndIncrement(); } else { // No heapArea is configured so just null out all caches tinySubPageHeapCaches = null; smallSubPageHeapCaches = null; normalHeapCaches = null; numShiftsNormalHeap = -1; } // other code ... } }
下面以createSubPageCaches为例,跟踪一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
privatestatic <T> MemoryRegionCache<T>[] createSubPageCaches( int cacheSize, int numCaches, SizeClass sizeClass) { if (cacheSize > 0 && numCaches > 0) { // 创建MemoryRegionCache数组!! 就是上图画的那个 @SuppressWarnings("unchecked") MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches]; for (int i = 0; i < cache.length; i++) { // 对于每一种大小的size都创建一个对应的MemoryRegionCache cache[i] = new SubPageMemoryRegionCache<T>(cacheSize, sizeClass); } return cache; } else { returnnull; } }
privateabstractstaticclassMemoryRegionCache<T> { .... /** * Allocate something out of the cache if possible and remove the entry from the cache. */ publicfinalbooleanallocate(PooledByteBuf<T> buf, int reqCapacity){ Entry<T> entry = queue.poll(); if (entry == null) { returnfalse; } // 使用entry初始化buf initBuf(entry.chunk, entry.nioBuffer, entry.handle, buf, reqCapacity);
// 对entry对象的池化,减少GC entry.recycle();
// allocations is not thread-safe which is fine as this is only called from the same thread all time. ++ allocations; returntrue; } .... }
privatevoidallocate(PoolThreadCache cache, PooledByteBuf<T> buf, finalint reqCapacity){ // 向上取整数(2的整数次幂) finalint normCapacity = normalizeCapacity(reqCapacity); // 判断是否小于一个pageSize if (isTinyOrSmall(normCapacity)) { // capacity < pageSize(8K) int tableIdx; PoolSubpage<T>[] table; boolean tiny = isTiny(normCapacity); if (tiny) { // < 512 , tiny的情况 // 先尝试从cache里分配!!!!! 如果能拿到并分配就直接返回了 if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) { // was able to allocate out of the cache so move on return; } // 从cache里没有拿到,则尝试从SubpagePool中去分配!!!!! // TinySizeTable对应tiny的table[0, 16, 32, 48, 64, ...] , idx对应table中的idx // 例如:reqCapacity=24, 则 24->32 对应[0, 16, 32, 48, 64, ...]中的idx为2 tableIdx = tinyIdx(normCapacity); table = tinySubpagePools; } else { // 512 <= 当前需要分配的byteBuf的大小 < 8K(8192) // 先尝试从cache里分配!!!!! 如果能拿到并分配就直接返回了 if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) { // was able to allocate out of the cache so move on return; } // // 从cache里没有拿到,则尝试从SubpagePool中去分配!!!!! // SmallSizeTable对应tiny的table[512,1024,2048,4096] , idx对应table中的idx tableIdx = smallIdx(normCapacity); table = smallSubpagePools; }
// 获取到对应Size的SubPage final PoolSubpage<T> head = table[tableIdx];
/** * Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and * {@link PoolChunk#free(long)} may modify the doubly linked list as well. */ synchronized (head) { final PoolSubpage<T> s = head.next; if (s != head) { assert s.doNotDestroy && s.elemSize == normCapacity; long handle = s.allocate(); assert handle >= 0; s.chunk.initBufWithSubpage(buf, null, handle, reqCapacity); incTinySmallAllocation(tiny); return; } }
if (normCapacity <= chunkSize) { // 如果待分配资源的大小 <= chunkSize, 那么依然可以从chunk中去分配!!!!! if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) { // was able to allocate out of the cache so move on return; } synchronized (this) { allocateNormal(buf, reqCapacity, normCapacity); ++allocationsNormal; } } else { // Huge的分配逻辑,单独走 // Huge allocations are never served via the cache so just call allocateHuge allocateHuge(buf, reqCapacity); } } }